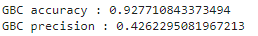Models building and training
The models building and training has been tried on a notebook found at:
/notebooks/3.0-ANTD-Models.ipynb
It was then implemented in scripts found at:
/src/models/
To know how to execute the scripts related to models, see Commands.
We used pickle to store our model as .pkl files, they can be found at:
/models
The first model we trained were basic models, we got more in depth with the XGBOOST model later on using MLFlow.
We started by splitting the processed training dataset into training and testing sets using sklearn.model_selection.train_test_split.
For the basic models, we will not explain every line of code as it is basic machine learning code defining the model, training it with .fit() and storing it using pickle.
For each models, we decided to take a look at the accuracy, precision and confusion matrix.
We decided to focus on the precision since we are trying to see if a person will be able to repay a loan or not
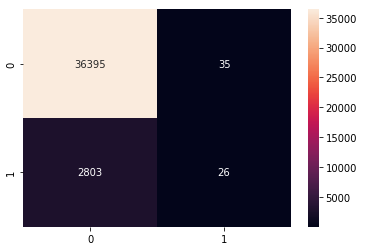
XGBOOST Model
from xgboost import XGBClassifier
## Building :
XGB = XGBClassifier(objective='binary:logistic', eval_metric="logloss", use_label_encoder=False, eta=0.3, subsample=1
, colsample_bytree=1)
## Training :
XGB.fit(X_train, y_train)
## Model storing
filenameXGB = 'models/base_XGB_model.pkl'
pickle.dump(XGB, open(filenameXGB, 'wb'))
The objective parameter is set to binary:logistic because we are trying to predict binary features
Logloss is the eval metrics used when predicting binary features
Label encoder is set to false because we don’t need to do it as we already did feature engineering
The next three values are parameters that will be detailed at XGBoost with MLFlow.
The model is store at: /models/base_XGB_model.pkl
Here are its results:

To see our advanced XGB model trained with MLFlow, see XGBoost with MLFlow.
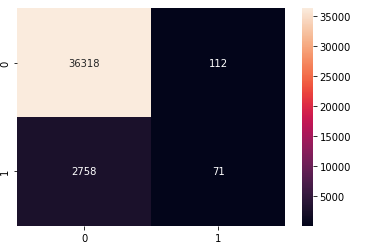
Random Forest Classifier
from sklearn.ensemble import RandomForestClassifier
## Building
RFC = RandomForestClassifier(n_estimators=200)
## Training
RFC.fit(X_train, y_train)
## Model storing
filenameRFC = 'models/RFC_model.pkl'
pickle.dump(RFC, open(filenameRFC, 'wb'))
The model is store at: /models/RFC_model.pkl
Here are its results:
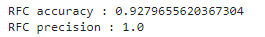
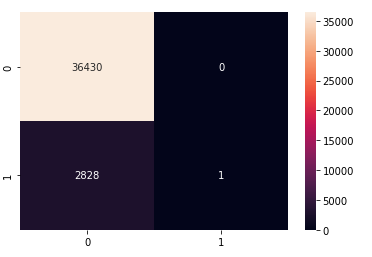
We couldn’t figure why we had a precision of 1 which is very unlickely to be real
Gradient Boosting Model
from sklearn.ensemble import GradientBoostingClassifier
## Building
GBC = GradientBoostingClassifier()
## Training
GBC.fit(X_train, y_train)
## Model storing
filenameGBC = 'models/GBC_model.pkl'
pickle.dump(GBC, open(filenameGBC, 'wb'))
The model is store at: /models/GBC_model.pkl
Here are its results: